In search of the least viewed article on Wikipedia
Wikipedia sure is popular. The most popular articles in a given week routinely get millions of views. But with 6 million plus articles, Wikipedia has plenty of room for articles about topics which are profoundly obscure, even downright boring. I should know, I’ve written dozens of them! Some of what I consider to be my finest contributions to Wikipedia are lucky to get a couple of views per day, for example:
Of my creations, the least popular seems to be Sunday reading periodical, an article about a Victorian magazine genre which averages around a dozen views per month.
Are there articles with even less popular appeal than that?
Though Wikipedia page view data is publicly available (as a massive raw data dump, and through an API), there’s unfortunately no easy way to sort out the least viewed pages, short of a very slow linear search for the needle in the haystack…
A smaller haystack
As a starting point, I grabbed 2021 pageview data for a random sample of about 32,000 Wikipedia articles. Maybe the properties of the least viewed articles in the sample will lead us to some heuristics we can use to narrow our search for the least viewed articles.
Here’s what the distribution of views looks like for that sample. I’ve used a logarithmic scale, since the values are widely spread out. The median article gets a little under 1,000 views annually. The average is around 13,000, thanks to the long tail.
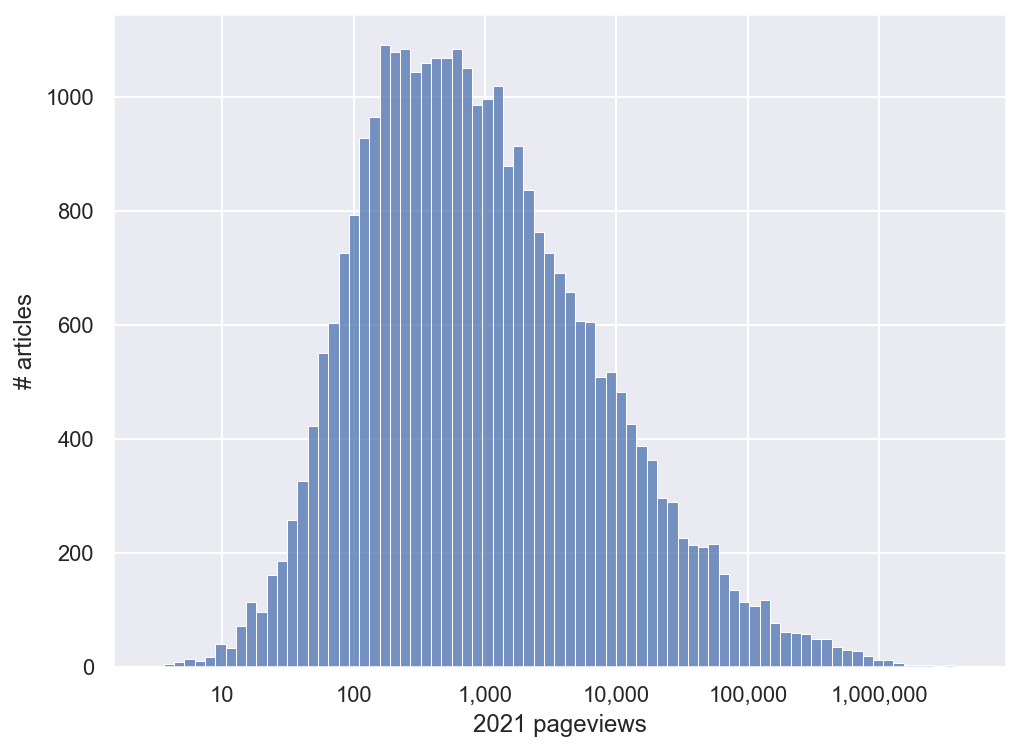
We have almost 100 articles in the sample whose total views in 2021 are in the single digits(!). Here’s a peek at the first few:
- Weimer Township (3 views)
- Goleh-ye Cheshmeh (4 views)
- Governor Terry (4 views)
But these are disambiguation pages - navigational aids which link to similarly named articles, but which aren’t themselves “real” articles, at least for our purposes. And in fact, all of the 50 least viewed pages in our dataset are disambiguation pages - they seem to have a notably lower floor on their pageviews than other articles.
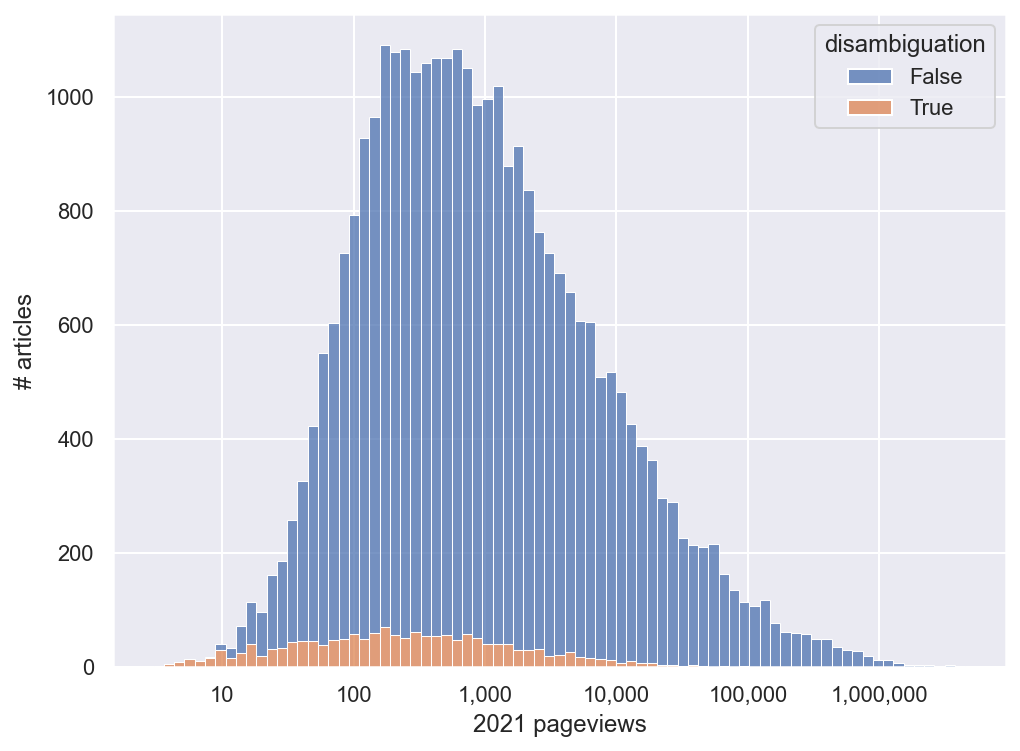
After filtering out disambiguation pages, we’re left with a small handful of articles with single-digit annual views (ranging from 7 to 9):
- Erygia sigillata, a moth species
- Hilarigona obscurata, a fly species (apparently aptly named)
- Loxocrambus hospition, a moth
- Makhoshin, an Iranian village
- Bojerud, a surname
- Scrobipalpula crustaria, yet another moth
These obscure 2 or 3 sentence stubs average less than one view per month! That figure is so small, I suspect most or all of those might come from readers hitting the “Random article” button. This would help explain why the least viewed pages in our sample are all disambiguation pages - the “Random article” button was coded to ignore disambiguation pages starting in 2015.
There’s an effective way we can test this hypothesis. And if it’s true, it will give us an important clue for finding the least viewed article on Wikipedia.
Interlude: how the “Random article” button works
Here’s a dark secret about Wikipedia: due to some peculiarities in its implementation, the “Random article” button isn’t as random as you might think.
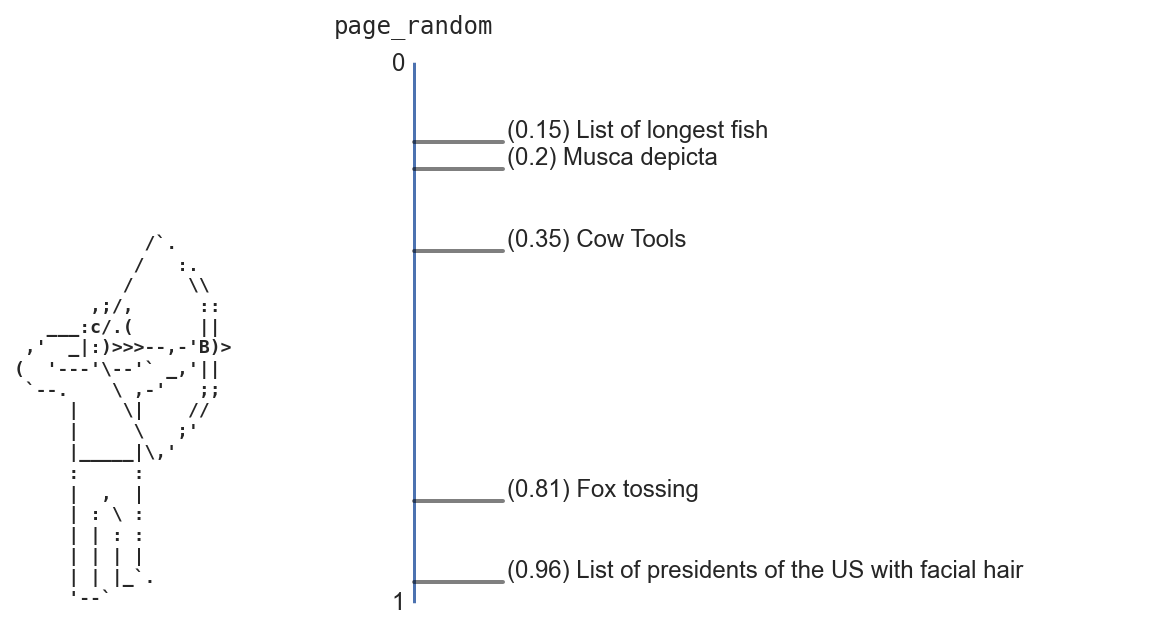
Whenever an article is created on Wikipedia, it’s assigned a random number between 0 and 1 (stored in the database as a field called page_random). As a toy example, suppose our encyclopedia has just 5 pages, with the following page_random values:
- List of longest fish: 0.15
- Musca depicta: 0.2
- Cow Tools: 0.35
- Fox tossing: 0.81
- List of presidents of the United States with facial hair: 0.96
When someone hits the “Random article” button, the server generates a random number between 0 and 1.
ASCII archer by jah/SSt via asciiart.eu.
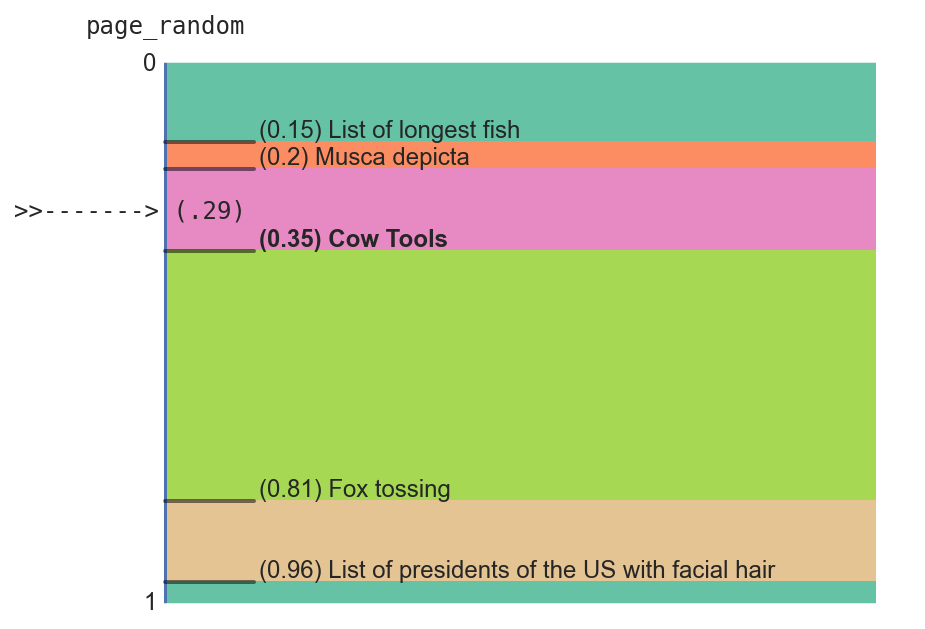
Let’s say our drunken archer’s arrow randomly lands at 0.29. The server will then search for and return the article in the database with the next-highest page_random value after 0.29. In this case, that’s Cow Tools.
ASCII arrow: own work.
As you might have surmised, this is not exactly a “fair” process. There is only a small range of values that will get us to Musca depicta: those between 0.15 and 0.2 (represented by the orange region above). It will only come up about 5% of the time, whereas Fox tossing will come up 46% of the time.
The probability of a given article being landed on is equal to the size of what I’ll call its random gap: the difference between the article’s page_random value and the next-lowest page_random value in the database. In the diagrams above, the size of each article’s colored rectangle corresponds to its random gap.
If the random article button is responsible for most of the pageviews for the project’s least popular articles, this leads to a couple testable predictions:
- That the least viewed articles will have unusually small random gaps
- That there is a (weak) correlation between random gap size and pageviews. This correlation should be most apparent when looking at the least viewed articles.
Are the least viewed articles in our sample “unlucky”?
Since there are around 6 million Wikipedia articles, the average random gap must be about 1/6,000,000, or 1.67e-7 in scientific notation. How big are the random gaps for the least viewed articles in our sample?
The least viewed article in the sample, Erygia sigillata, has a page_random value of 0.500764585777. The article Katherine Hanley is right on its tail with a value of 0.500764582314, which is just 0.000000003 less, or 3e-9 in scientific notation. This is 98% smaller than the average random gap. In other words, Erygia sigillata is an extremely unlucky article as far as the “Random article” button is concerned! It’s 50 times less likely to be landed on than an average article.
The random gaps for the 5 other articles in our sample with single-digit annual views are: 3e-9, 9e-9, 8e-9, 4e-9, 8e-9, 2e-8. All about an order of magnitude smaller than average. Quite a strong pattern!
Is there a correlation between random gap and views?
In the grand view of our sample of 32,000 articles, it seems like a wash:
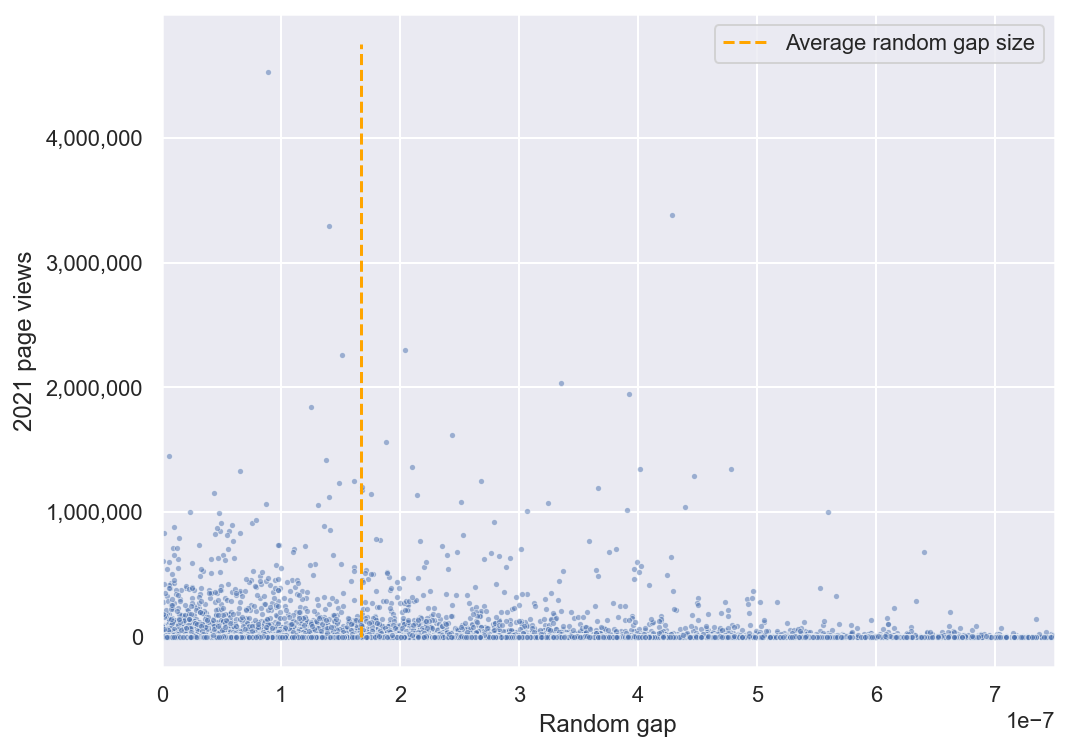
(If anything, it might look like articles with smaller gaps get more views, but this is just an artefact of the fact that most articles have gaps which are close to the average.)
But we predicted that random gap will only have a noticeable effect on the floor of pageviews. Let’s do an extreme zoom-in on the very bottom of the plot, looking only at articles with less than 200 annual views:
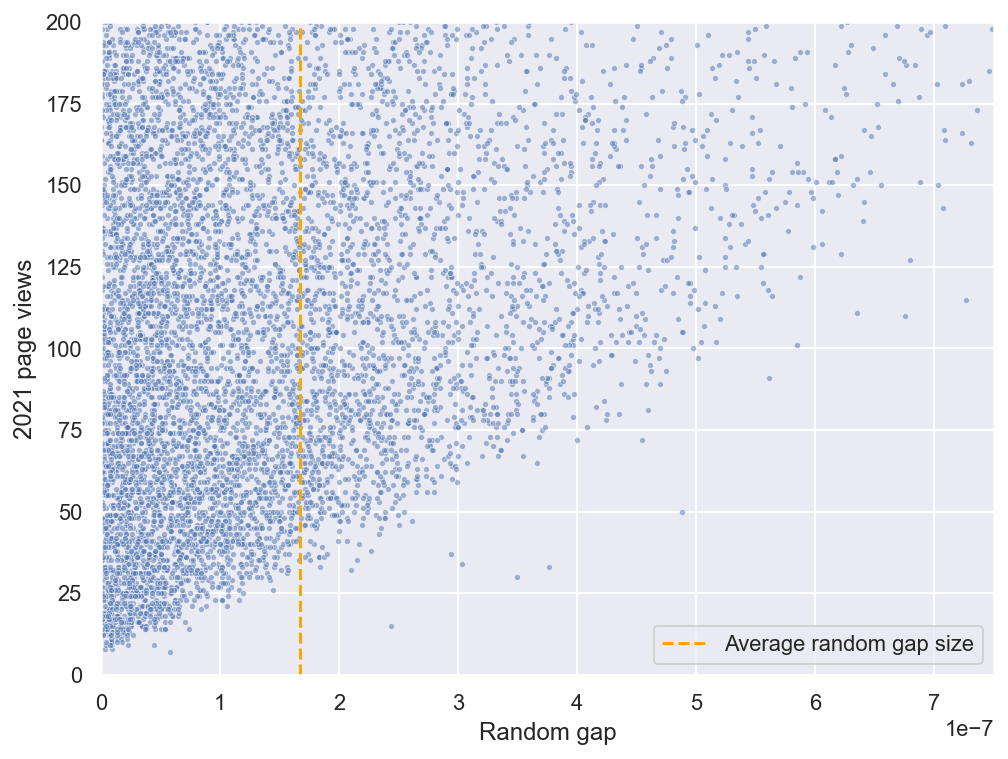
An even clearer picture emerges if we limit our analysis to articles which are a priori probably uninteresting, such as short articles about moth species (sorry, entomologists). Here’s a scatterplot of random gap vs. total views in 2021 for all ~1,500 pages in Category:Phaegopterina stubs:
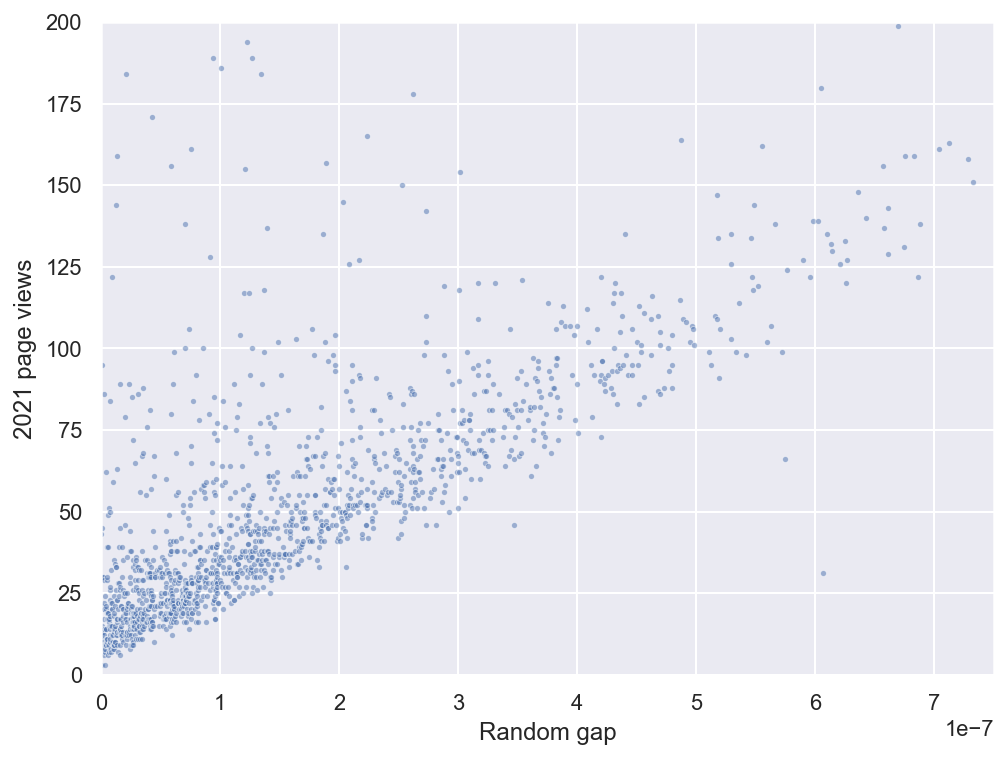
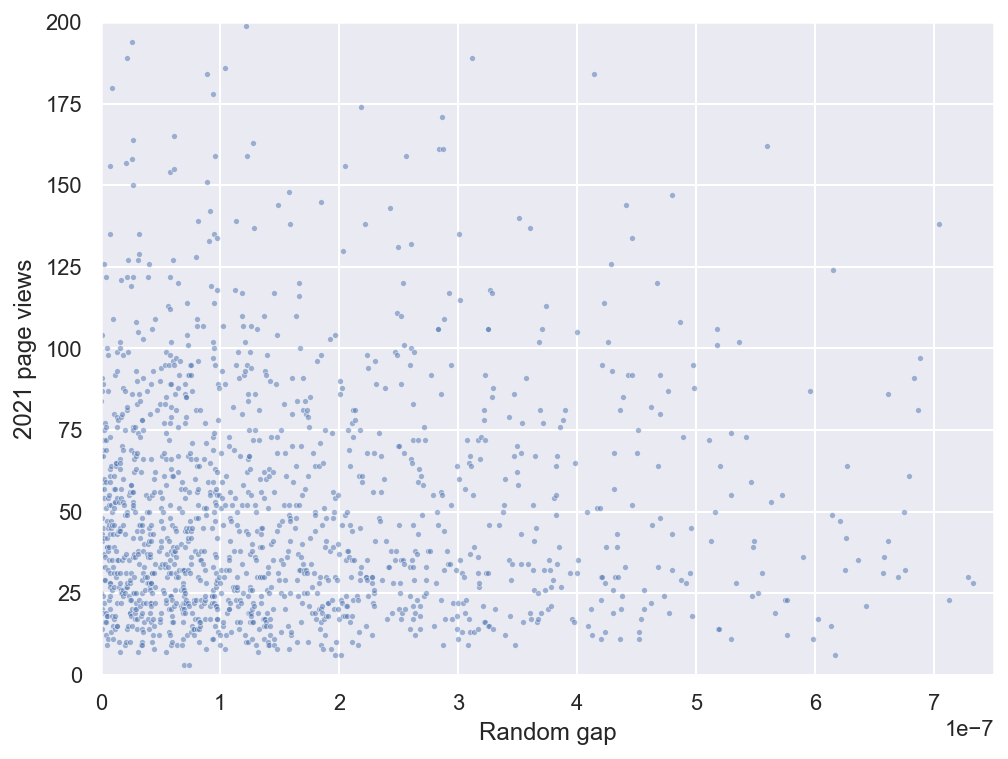
This must be how those scientists felt when they first saw a graph of the cosmic microwave background radiation! (To get a sense of how coherent this pattern is, here is what the same graph would look like under the null hypothesis of no association between random gap and page views. I synthesized this by randomly permuting the pageview values in the dataset.)
{kind=link}
The least popular articles of 2021
Based on our findings above, the least viewed articles on Wikipedia are not going to be merely about topics with little popular interest - they must also be “unlucky” in the sense of having very small random gaps.
We can considerably narrow our search for the least viewed articles of 2021 by limiting our analysis to pages with small random gaps. I set a threshold of 1.7e-8, or about 1/10th of the average gap size.
Of these 600,000 least lucky articles, all received at least a few views in 2021. The booby prize for least popular article of 2021 is shared by two articles which received exactly 3 probably-human pageviews:
- Trichromia phaeocrota (random gap: 4e-9)
- Opharus corticea (random gap: 1e-9)
If you guessed that these are both moth species, you would be right.
Patterns in unpopular articles
You can check out a larger leaderboard of the 500 least viewed articles here. The list is remarkably consistent in its subject matter:
- A significant majority of them are about species or other taxons of insects (plus 17 gastropods, and one fungus).
- The next most common category is obscure geographical features, especially (for some reason) towns in Iran and Sri Lanka. My favourite of these is the deliciously laconic Kälberbuckel.
- One other recurring genre are set index articles like C24H31FO5, Dottley, Sukmanovka, and Great polemonium. (A set index article is a page which looks and functions like a disambiguation page but isn’t, because of reasons.)
There are a small number of articles not falling into the previously-mentioned categories. Some feel like living fossils from an earlier age of Wikipedia when standards of demonstrated notability were looser. It’s a little questionable whether articles like DMZ//38 or EuroNanoForum 2009 could weather a deletion discussion today.
Why so many moths?
The Wikipedia community’s policies and practices around which articles are “notable” (worthy of an article) and which get deleted have a healthy pragmatism to them. If Wikipedia allowed articles about anything, we would see a lot more articles about obscure garage bands, businesses, and living people. The authors of these articles would not be disinterested scholars writing with the goal of expanding the largest collection of knowledge on the internet. Rather, we would get a lot of editors with conflicts of interest, using Wikipedia for publicity, profit, or to settle a score. Before the community tightened up its notability criteria, it was not so uncommon in the very early days of the project to see blatant autobiographies, advertisements, or attack pages. Here are just a few examples based on real articles from Wikipedia’s early years which have since been deleted (names and details have been altered to protect the “innocent”):
Mian Amir Rashid is the youngest elected chairman of Pakistan chapter of Mensa. He assumed the post in 2001 at the age of 23. Under his tenure Mensa has grown very rapidly and now operating in 5 cities of Pakistan including Karachi, Lahore & Capital Islamabad
Mr. Rashid is a Public Relations & Marketing consultant by profession.
Union Cab is a cab company in Saint Paul, MN. They can be reached at www.unioncab.biz or 555-242-2000.
–Sam
Trevor Shelby is a Canadian businessman and robotics engineer. He is the founder and CEO of Polybonk.
Mr. Shelby and Polybonk were the subject of a Human Rights Tribunal of Quebec inquiry alleging discrimination in employment practices.[1] During the course of the inquiry, Mr. Shelby’s professional qualifications were called into question.[2]
Shelby also created controversy in a highly publicized case of road rage. According to the police report, he menaced another driver with a tennis racquet while hurling obscenities.[3]
The Ghosties are a small band from Melbourne. Nick sings and plays guitar, Sumeet plays bass if he hasn’t been naughty, Clark plays guitar properly and Kris makes the band seem good on the drums.
With their trademark songs Dear Robby, and Firecracker, this band are very cool, and their unmeasurable spontaneity is the stuff of legends. Learn more about The Ghosties on their website. The Forum should contain the dates and times of any upcoming gigs.
Over time, Wikipedia has developed a strong immune response against those who would try to use it for nefarious purposes, in the form of strict sourcing requirements for the sorts of topics shown above (e.g. living people, companies, bands). The existence of, say, the Union Cab company may be verifiable via primary sources, such as local business listings, but that’s not enough to secure it a place on Wikipedia. It needs significant coverage in multiple independent secondary sources. It makes sense then that we see almost no articles about these sorts of topics in the bottom 500. Any subject that meets these strict sourcing requirements is probably going to be of interest to someone beyond just those surfing the “Random article” button.
On the other hand, no-one has yet come up with a way to monetize a topic like Pseudoneuroterus mazandarani or use it to push a contentious point of view. Hence articles about species and populated places are generally not deleted, even if the topic is only weakly sourced – and most of our unpopular articles are weakly sourced, often having just a single citation to a primary source such as a database or gazetteer, or a passing mention in a single book or journal article.
Because the bar for these topics is so low, many of these articles feel a little soulless, having the appearance of being popped out via a mechanical (perhaps even fully automated) process. For example, the 12-word stub Pottallinda (5 views last year) was created on 18 January 2011 by User:Ser Amantio di Nicolao, who happens to be the most active editor in all of Wikipedia (as measured by number of edits). Within 60 seconds of creating this page, the same editor also created Polmalagama, Polommana, Polpitiya, Polwatta, and dozens of other substantially identical articles.
But hey, these hyper-obscure, tiny articles aren’t doing any harm (other than maybe disappointing the dozen people per year who land on them, rather than a more interesting fleshed-out article, when hitting the “Random article” button), and they lay a groundwork that other editors might build on in the future.
The pageview data used in this post, as well as the code used to scrape and analyse it, is available on GitHub here.
Tagged: Wikipedia