Dissecting Google's Billion Word Language Model Part 2: Convolutional Filters
Last week I showed some visualizations of character embeddings in Google’s recently released neural language model. This post will be about the next stage in the pipeline - convolutional filters.
I put together some (ugly) visualizations of convolutional filters here (use the links at the top to see filters of other widths).
If you don’t know what you’re looking at, this article has a pretty lucid explanation of convolutional nets and their application to natural language processing. If you want to know more about the overall architecture of the lm_1b model, my previous post has a brief overview and links to the relevant papers.
Observations
Overall, the filters are surprisingly (and disappointingly) hard to interpret. When I was playing with character-level RBMs, I made a similar visualization of feature detectors for an RBM model trained on GitHub repository names: the Hidden Unit Zoo. Among those feature detectors, there were a lot of pleasantly interpretable ones (there are links to a few dozen of them at the top of the Zoo).
One reason the weights alone are less interpretable in this case is that there’s a lot more noise. lm_1b is not a generative model over characters, so there’s no downward pressure on implausible weights. For example, the model is not penalized for having filters with high weights on the ‘end of word’ character at position 0. It will never see an input string having that character at the first position, so its weight doesn’t matter (but may still be driven up because of the proximity of its character embedding to other characters). In fact, this kind of thing happens a lot (but I’ve ommitted from the visualizations weights on characters in positions in which they logically can’t appear).
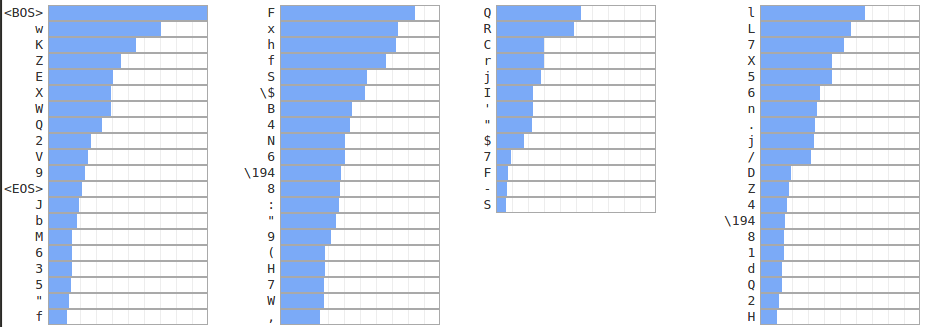
But even ignoring the weights and just looking at the top words per filter, there’s usually not much cohesion. And I’m honestly not sure why. Whatever the model is doing, it inarguably works, it’s just disappointing that it eludes tidy description.
A few good filters
Here are a few filters that struck me as at least a little interpretable or interesting:
- 1-17 seems to be dead. It has no weights with magnitude above the bias of -0.08. Curious! (1-5 also looks dead, but is actually just highly selective. It has a weight of 0.1 on the byte with decimal value 230, but I excluded most non-ASCII bytes from the tables for readability.)
- 1-29: ‘k’ detector. Many of the width-1 filters only activate for one or two characters.
- 3-54 has a high affinity for years
- 4-107 gives high scores to
^\d\d-, in words like “25-year-old”, or “30-year”. - 5-5: first halves of hyphenated words. (Note the size of the weight on the hyphen in the last position relative to all the other weights.)
- 5-30: proper nouns. Very high weights on capital letters in position 1, but not in the other positions. (Also, the most significant negative weights are on lowercase letters in position 1).
- 5-47: sports scores?
Most filters seem to be non-zero for around 10-20% of words. Generally the most interesting filters tend to be on the lower end of that (i.e. more selective). Also, lower width filters tend to be more selective (width 1 filters fall around 0-10%).
Nitty gritty details
The lm_1b model uses a total of 4096 convolutional filters. The distribution of filter widths is:
- 1: 16
- 2: 32
- 3: 64
- 4: 128
- 5: 256
- 6: 512
- 7: 2048
I just showed up to the first 128 filters for each filter width.
Following the example of (Kim 2015) the lm_1b model does max pooling over the entire extent of the string. This was a little surprising to me - essentially, the layer upstream from the filters only sees an unordered bag of character n-grams!
Whereas (Kim 2015) used tanh, lm_1b uses the relu activation function for its convolutional units.
You may have noticed that the visualizations show weights per character, whereas I said previously that the convolutional filters see character embeddings, not the raw characters themselves. Since the character embeddings are just a linear transformation over the input characters, it’s possible to multiply the character embeddings and the convolutional weights to get the equivalent weights over characters. (e.g. if ‘x’ has 2-d character embedding (1, -1), and a filter has weights (1, .5) over the character embedding dimensions, this is equivalent to the filter having a weight of 1*1 + -1*.5 = .5 on character ‘x’).
Tagged: Machine Learning, Data Visualization